Решил погонять на время In Place Element Structure в следующем контексте.
Получилось, что время выполнения цикла с этой стурктурой даже немного больше чем без нее. Плюс еще видно, что выделяется какой-то буфер в структуре, от как.
In Place Element Structure дает ли реальные преимущества?
-
Chupakabra

")
- professional

- Сообщения: 360
- Зарегистрирован: 21 янв 2009, 10:50
- Награды: 1
- Версия LabVIEW: 2015
- Откуда: Москва
- Поблагодарили: 4 раза
- Контактная информация:
-
mzu2006

")
")
- doctor

- Сообщения: 2456
- Зарегистрирован: 16 авг 2008, 02:12
- Награды: 3
- Версия LabVIEW: 7.1 10 11 12
- Откуда: St-Petersburg (RU), Phila, Boston, Washington DC
- Контактная информация:
Re: In Place Element Structure дает ли реальные преимуществ
Здесь дело не в структуре а в обвязке этой структуры.
1. Операция индексации "в ручную", достаточно "дорогая" по времени.
2. Выделение буфера мне тоже непонятно
3. Автоиндексация на границе счётного цикла очень эффективное средство.
Я использую "In place element structure" только для работы с DVR.
1. Операция индексации "в ручную", достаточно "дорогая" по времени.
2. Выделение буфера мне тоже непонятно
3. Автоиндексация на границе счётного цикла очень эффективное средство.
Я использую "In place element structure" только для работы с DVR.
Правила форума (Forum rules in Russian)
rm -rf /mnt/windows
rm -rf /mnt/windows
-
Chupakabra
- professional
- Сообщения: 360
- Зарегистрирован: 21 янв 2009, 10:50
- Награды: 1
- Версия LabVIEW: 2015
- Откуда: Москва
- Поблагодарили: 4 раза
- Контактная информация:
Re: In Place Element Structure дает ли реальные преимуществ
Спасибо за ответы. Тогда еще вот такой вопрос.mzu2006 писал(а):Здесь дело не в структуре а в обвязке этой структуры.
1. Операция индексации "в ручную", достаточно "дорогая" по времени.
2. Выделение буфера мне тоже непонятно
3. Автоиндексация на границе счётного цикла очень эффективное средство.
Я использую "In place element structure" только для работы с DVR.
Для случая изображенного на рисунке ниже, какой вариант более оптимален?
Первый наверное по памяти, второй по производительности?
И еще дает ли что использование вложенной (т.е. внутри первой) In place element structure, как показано в варианте 1?
- Вложения
-
-
Borjomy_1
")
")
- doctor
- Сообщения: 2211
- Зарегистрирован: 28 июн 2012, 09:32
- Награды: 3
- Версия LabVIEW: 2009..2020
- Откуда: город семи холмов
- Благодарил (а): 27 раз
- Поблагодарили: 27 раз
Re: In Place Element Structure дает ли реальные преимуществ
Тема интересная, кстати. С чем регулярно сталкиваюсь: Есть большой массив (размером под 100000 элементов) кластера, в котором, в свою очередь, несколько массивов, строки. Если делать в лоб (как вариант 2), то скорость работы существенно падает. Спасает вариант 1. Если внимательно присмотреться, то видно, что расходы на память в первом случае радикально меньше.
Эта структура дает выигрыш, когда объемы данных значительны. Иначе заморачиваться особо смысла нет.
Эта структура дает выигрыш, когда объемы данных значительны. Иначе заморачиваться особо смысла нет.
-
IvanLis

")
")
")
- guru

- Сообщения: 5463
- Зарегистрирован: 02 дек 2009, 17:44
- Награды: 7
- Версия LabVIEW: 2015, 2016
- Откуда: СССР
- Благодарил (а): 28 раз
- Поблагодарили: 87 раз
Re: In Place Element Structure дает ли реальные преимуществ
проводили мы тут практический эксперимент: In Place Element StructureBorjomy_1 писал(а):Тема интересная, кстати.
весьма интересные результаты
Знание нескольких принципов освобождает от знания многих фактов!
Правила форума
Как добавить в сообщение картинку или файл
Конвертация / версий (форматов) VI
Как правильно задать вопрос...
Правила форума
Как добавить в сообщение картинку или файл
Конвертация / версий (форматов) VI
Как правильно задать вопрос...
-
Borjomy_1
- doctor
- Сообщения: 2211
- Зарегистрирован: 28 июн 2012, 09:32
- Награды: 3
- Версия LabVIEW: 2009..2020
- Откуда: город семи холмов
- Благодарил (а): 27 раз
- Поблагодарили: 27 раз
Re: In Place Element Structure дает ли реальные преимуществ
Насколько я понимаю способы распределения памяти в  , неправильно экстраполировать тестирование на массиве элементов фиксированного размера на общие выводы о эффективности In Place.
, неправильно экстраполировать тестирование на массиве элементов фиксированного размера на общие выводы о эффективности In Place.
-
IvanLis
- guru
- Сообщения: 5463
- Зарегистрирован: 02 дек 2009, 17:44
- Награды: 7
- Версия LabVIEW: 2015, 2016
- Откуда: СССР
- Благодарил (а): 28 раз
- Поблагодарили: 87 раз
Re: In Place Element Structure дает ли реальные преимуществ
Borjomy_1 писал(а):Насколько я понимаю способы распределения памяти в
Вы можете предложить свой вариант и показать полученные результаты
Что получилось, то и показал.
Знание нескольких принципов освобождает от знания многих фактов!
Правила форума
Как добавить в сообщение картинку или файл
Конвертация / версий (форматов) VI
Как правильно задать вопрос...
Правила форума
Как добавить в сообщение картинку или файл
Конвертация / версий (форматов) VI
Как правильно задать вопрос...
-
mzu2006
- doctor
- Сообщения: 2456
- Зарегистрирован: 16 авг 2008, 02:12
- Награды: 3
- Версия LabVIEW: 7.1 10 11 12
- Откуда: St-Petersburg (RU), Phila, Boston, Washington DC
- Контактная информация:
Re: In Place Element Structure дает ли реальные преимуществ
Я тоже не понял. Покажите Ваш код.
Правила форума (Forum rules in Russian)
rm -rf /mnt/windows
rm -rf /mnt/windows
-
AndreyDmitriev
- VIP

- Сообщения: 1337
- Зарегистрирован: 03 фев 2010, 00:42
- Награды: 6
- Версия LabVIEW: 6.1 - 2024
- Откуда: Германия
- Благодарил (а): 1 раз
- Поблагодарили: 42 раза
- Контактная информация:
Re: In Place Element Structure дает ли реальные преимуществ
Конкретно InPlace структуру следует рассматривать как средство для сокращения расхода памяти при необоснованном выделении дополнительных буферов. Рассматривать её в качестве "турбо кнопки" было бы ошибочно, хотя в некоторых случаях она даёт прирост в производительности.
Давайте разбираться. Вообще говоря элементы для работы с массивами, строками, кластерами и иже с ними можно разделить на две группы - немодифицирующие, то есть операции чтения - Index Array, Cluster Unbundle, и т.д. и модифицирующие, то бишь операции записи - Replace Array, Delete, Cluster Bundle и т.д. При комбинировании этих элементов LabVIEW пытается по возможности уменьшить количество копий данных в памяти и использовать уже имеющиеся и выделенные буферы. Другое дело, что LabVIEW это не всегда удаётся, и иногда ей надо помочь - InPlace структура - это как раз тот костыль, который надо подставить, когда компилятор в затруднении.
Для начала вот такой пример:
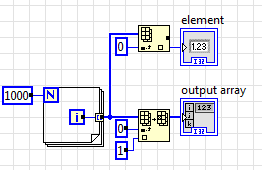
Как мы видим, у нас массив после цикла разделяется на две ветви, однако копии не создаётся. При этом нулевой элемент заменяется единицей, однако Index Array возвращает нуль, что ожидаемо. Почему не единицу, ведь буфер вроде как тот же? Состояния гонки здесь не возникает, потому что LabVIEW сначала выполняет операцию чтения, и лишь потом - операцию записи, хотя на блок диаграмме последовательность исполнения никак не задана. Стоит жёстко задать порядок выполнения - и будет выделен буфер, что удвоит количество используемой памяти:
Если новый буфер не выделялся бы, то мы бы с удивлением обнаружили бы в нулевом элементе единицу при чтении во втором окне фрейма.
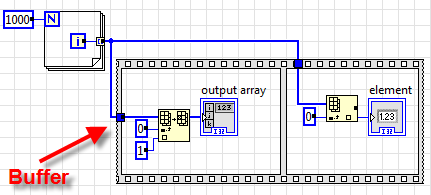
Другой пример - две операции чтения и две записи:
Тут я кружком отметил место, где выделяется новый буфер. Это происходит оттого, что у нас есть две операции записи, и результат второй операции (output array 2) не должен менять массив "output array". Ну и так далее.
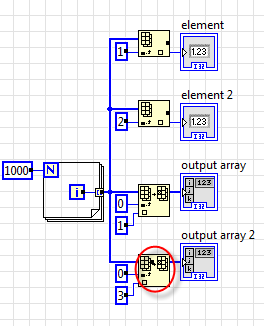
Едем дальше. Часто операции чтения и записи комбинируются вот таким образом:
Здесь дополнительных буферов не выделяется и замена этой конструкции на InPlace структуру в смысле экономии памяти нам ничего не даст, кроме уменьшения количества проводников. С точки зрения операций - в Inplace будут использованы те же самые Index/Replace, так что в производительности мы особого выигрыша не получим, что и наблюдается на некоторых тестах. Боле того, на старых версиях InPlace структура может даже привести к небольшому замедлению по сравнению с Index/Replace, однако в LabVIEW 2011 по производительности они сравняются. Впрочем я наблюдал ситуации, когда InPlace структура давала определённый выигрыш в производительности - это, по видимому зависит от того, как компилятор отработает.
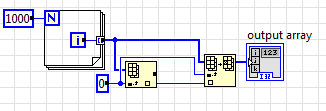
Теперь попробуем найти ситуацию, когда InPlace "работает". Давайте чуть изменим наш код:
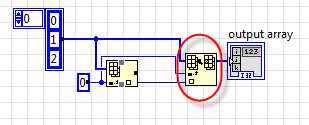
Вроде ничего принципиально не изменилось, однако, наткнувшись на константу, LabVIEW выделила нам буфер для операции записи, совершенно не нужный. Возьмите также на земетку, что буфер у Replace Array появился от изменения кода источника данных - это значит, что изменив код на одном конце даграммы, можно получить изменения в совершенно неожиданном месте. Тем не менее результат - количество расходуемой памяти возросло вдвое, кроме того, код стал медленнее (на массиве размером этак в сотню мегабайт десять-двадцать миллисекунд мы, вероятно потеряем).
Вот для этой ситуации нам и нужна InPlace структура:
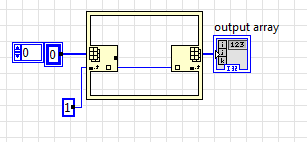
Здесь дополнительного расхода памяти нет, код этот выполняется значительно быстрее. Сравните выделение буферов на этом коде со скриншотом выше и вы увидите разницу.
Вообще National Instruments пишет об этой структуре довольно расплавчато - она уменьшит количество расходуемой памяти "в некоторых случаях". Будет она "работать" или нет и даст ли преимущество — зависит от внешних элементов, наличия других модифицирующих элементов и порядка их выполнения и т.д. В некоторых случаях можно запросто получить дополнительный буфер на входе в InPlace структуру. Единственное, что гарантируется - внутри самой структуры копии массива создано не будет.
Я использую эту структуру довольно часто хотя бы потому, что она весьма удобна - операции чтения записи сгруппированы рамкой, меньшее количество проводников. В случае больших массивов имеет смысл проконтролировать выделение буферов. В случае небольших массивов - мне в общем-то пофиг, тут просто удобство пользования на первом плане. Побочных эффектов этой структуры я пока не замечал. Ну и также это средство работы с DVR, как уже отмечалось.
Отдельно имеет смысл поговорить вот об этом буфере - в самом первом посте был вопрос:
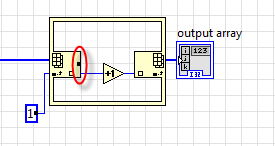
Это происходит оттого, что LabVIEW работает с элементами массива "по значению", каждый раз перебрасывая элемент во временный буфер. Это хорошо видно и на ассемблерном листинге. Ну а в терминах язака Си там происходит всегда что-то вроде
int temp;
int arr[1000];
temp = arr[0];
temp = temp + 1;
arr[0] = temp;
В то время как нормальный компилятор просто сделал бы
int arr[1000];
arr[0]++;
Последния версия LabVIEW выдаёт довольно производительный код, но до скорости интеловского или майкрософтовского компиляторов ещё ой как далеко, так что если нужна действительно высокая скорость исполнения, то по-прежнему придётся генерять свою DLL.
Вообще когда мы упираемся в чересчур большой расход памяти или недостаточную производительность, то надо каждый конкретный случай рассматривать индивидуально. Универсальных рецептов тут нет. В общем случае не стоит использовать Build Array - это очень "дорогая" операция. Массивы в циклы загонять через сдвиговые регистры. При автоиндексации на границах цикла контролировать, что не создаётся буфер на выходе - вот, к примеру в третьем посте сверху мы видим, что буфера создаются на выходе двух вложенных циклов - это аргумент в пользу замены автоиндексации на сдвиговые регистры, либо упрощения типа данных. Использовать опять же InPlace структуру. Вообще ситуация, когда производительности не хватает "чуть-чуть" - она довольно редкая (в моей практике во всяком случае). Либо идёт работа с небольшими внутренними массивами, где производительность не важна, либо с очень большими объёмами, где производительность никакими InPlace структурами не вытянешь - тогда приходится подключать внешний код. Да и вообще - оптимизация без причины — признак ..., ну вы поняли .
.
По сути вопроса, прозвучавшего в третьем посте:
В данном случае вот такая структура неоптимальна, потому что идёт выделение буферов:
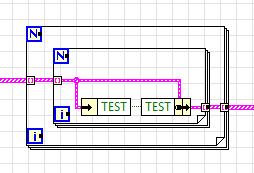
Более оптимально (причём не только с точки зрения расхода памяти, но и с точки срения производительности) сделать как-то вот так:
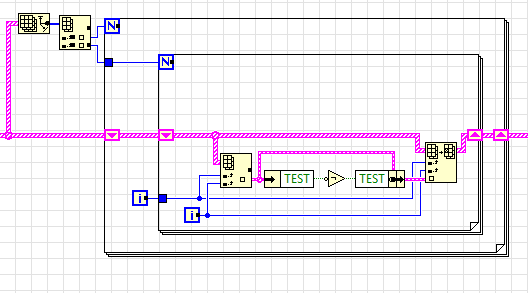
InPlace структура в смысле экономии памяти нам тут ничего не даст, но посмотрите, насколько красивее стал код, да и работает он едва ли не вдвое быстрее (к сожалению разумного объяснения тут нет, единственное, что приходит в голову - дизассемблировать код да сравнить, однако делать это лень):
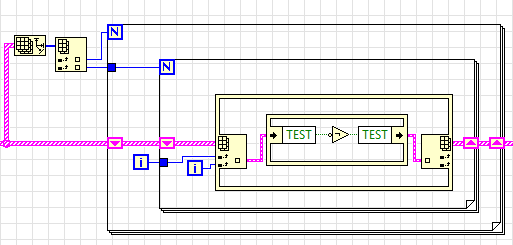
Ну и на закуску - многие (и я в том числе) ленятся подключать терминал N, а используют автоиндексацию для задания количества итераций цикла for, а напрасно:
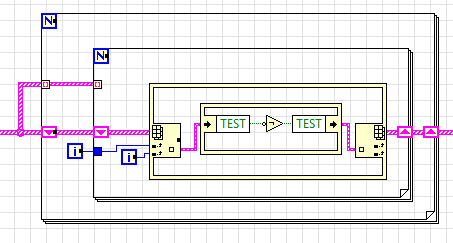
Двойной расход памяти, так как в сдвиговый регистр отправилась копия массива, плюс очевидные пенальти по производительности.
Дисклаймер - на вопросы "почему вот здесь буфер выделяется а вот тут - нет и там быстрее - а сям медленнее" отвечать довольно сложно, так как это лежит в большой степени на совести компилятора и небольшая модификация программы может привести к кардинальным изменениям. Где кроется истина - знает лишь NI, так что всё вышенаписанное не воспринимайте как аксиому - это просто пища для размышлений.
Ну и список литературы, ессно, там по большей части всё изложено:
In Place Element Structure
Array Index / Replace Elements Border Node
In Place Element Structures: Increasing Memory Efficiency
VI Memory Usage
Memory Management for Large Data Sets (раздел "Reducing Copies of Large Data Sets")
Давайте разбираться. Вообще говоря элементы для работы с массивами, строками, кластерами и иже с ними можно разделить на две группы - немодифицирующие, то есть операции чтения - Index Array, Cluster Unbundle, и т.д. и модифицирующие, то бишь операции записи - Replace Array, Delete, Cluster Bundle и т.д. При комбинировании этих элементов LabVIEW пытается по возможности уменьшить количество копий данных в памяти и использовать уже имеющиеся и выделенные буферы. Другое дело, что LabVIEW это не всегда удаётся, и иногда ей надо помочь - InPlace структура - это как раз тот костыль, который надо подставить, когда компилятор в затруднении.
Для начала вот такой пример:
Как мы видим, у нас массив после цикла разделяется на две ветви, однако копии не создаётся. При этом нулевой элемент заменяется единицей, однако Index Array возвращает нуль, что ожидаемо. Почему не единицу, ведь буфер вроде как тот же? Состояния гонки здесь не возникает, потому что LabVIEW сначала выполняет операцию чтения, и лишь потом - операцию записи, хотя на блок диаграмме последовательность исполнения никак не задана. Стоит жёстко задать порядок выполнения - и будет выделен буфер, что удвоит количество используемой памяти:
Если новый буфер не выделялся бы, то мы бы с удивлением обнаружили бы в нулевом элементе единицу при чтении во втором окне фрейма.
Другой пример - две операции чтения и две записи:
Тут я кружком отметил место, где выделяется новый буфер. Это происходит оттого, что у нас есть две операции записи, и результат второй операции (output array 2) не должен менять массив "output array". Ну и так далее.
Едем дальше. Часто операции чтения и записи комбинируются вот таким образом:
Здесь дополнительных буферов не выделяется и замена этой конструкции на InPlace структуру в смысле экономии памяти нам ничего не даст, кроме уменьшения количества проводников. С точки зрения операций - в Inplace будут использованы те же самые Index/Replace, так что в производительности мы особого выигрыша не получим, что и наблюдается на некоторых тестах. Боле того, на старых версиях InPlace структура может даже привести к небольшому замедлению по сравнению с Index/Replace, однако в LabVIEW 2011 по производительности они сравняются. Впрочем я наблюдал ситуации, когда InPlace структура давала определённый выигрыш в производительности - это, по видимому зависит от того, как компилятор отработает.
Теперь попробуем найти ситуацию, когда InPlace "работает". Давайте чуть изменим наш код:
Вроде ничего принципиально не изменилось, однако, наткнувшись на константу, LabVIEW выделила нам буфер для операции записи, совершенно не нужный. Возьмите также на земетку, что буфер у Replace Array появился от изменения кода источника данных - это значит, что изменив код на одном конце даграммы, можно получить изменения в совершенно неожиданном месте. Тем не менее результат - количество расходуемой памяти возросло вдвое, кроме того, код стал медленнее (на массиве размером этак в сотню мегабайт десять-двадцать миллисекунд мы, вероятно потеряем).
Вот для этой ситуации нам и нужна InPlace структура:
Здесь дополнительного расхода памяти нет, код этот выполняется значительно быстрее. Сравните выделение буферов на этом коде со скриншотом выше и вы увидите разницу.
Вообще National Instruments пишет об этой структуре довольно расплавчато - она уменьшит количество расходуемой памяти "в некоторых случаях". Будет она "работать" или нет и даст ли преимущество — зависит от внешних элементов, наличия других модифицирующих элементов и порядка их выполнения и т.д. В некоторых случаях можно запросто получить дополнительный буфер на входе в InPlace структуру. Единственное, что гарантируется - внутри самой структуры копии массива создано не будет.
Я использую эту структуру довольно часто хотя бы потому, что она весьма удобна - операции чтения записи сгруппированы рамкой, меньшее количество проводников. В случае больших массивов имеет смысл проконтролировать выделение буферов. В случае небольших массивов - мне в общем-то пофиг, тут просто удобство пользования на первом плане. Побочных эффектов этой структуры я пока не замечал. Ну и также это средство работы с DVR, как уже отмечалось.
Отдельно имеет смысл поговорить вот об этом буфере - в самом первом посте был вопрос:
Это происходит оттого, что LabVIEW работает с элементами массива "по значению", каждый раз перебрасывая элемент во временный буфер. Это хорошо видно и на ассемблерном листинге. Ну а в терминах язака Си там происходит всегда что-то вроде
int temp;
int arr[1000];
temp = arr[0];
temp = temp + 1;
arr[0] = temp;
В то время как нормальный компилятор просто сделал бы
int arr[1000];
arr[0]++;
Последния версия LabVIEW выдаёт довольно производительный код, но до скорости интеловского или майкрософтовского компиляторов ещё ой как далеко, так что если нужна действительно высокая скорость исполнения, то по-прежнему придётся генерять свою DLL.
Вообще когда мы упираемся в чересчур большой расход памяти или недостаточную производительность, то надо каждый конкретный случай рассматривать индивидуально. Универсальных рецептов тут нет. В общем случае не стоит использовать Build Array - это очень "дорогая" операция. Массивы в циклы загонять через сдвиговые регистры. При автоиндексации на границах цикла контролировать, что не создаётся буфер на выходе - вот, к примеру в третьем посте сверху мы видим, что буфера создаются на выходе двух вложенных циклов - это аргумент в пользу замены автоиндексации на сдвиговые регистры, либо упрощения типа данных. Использовать опять же InPlace структуру. Вообще ситуация, когда производительности не хватает "чуть-чуть" - она довольно редкая (в моей практике во всяком случае). Либо идёт работа с небольшими внутренними массивами, где производительность не важна, либо с очень большими объёмами, где производительность никакими InPlace структурами не вытянешь - тогда приходится подключать внешний код. Да и вообще - оптимизация без причины — признак ..., ну вы поняли
По сути вопроса, прозвучавшего в третьем посте:
В данном случае вот такая структура неоптимальна, потому что идёт выделение буферов:
Более оптимально (причём не только с точки зрения расхода памяти, но и с точки срения производительности) сделать как-то вот так:
InPlace структура в смысле экономии памяти нам тут ничего не даст, но посмотрите, насколько красивее стал код, да и работает он едва ли не вдвое быстрее (к сожалению разумного объяснения тут нет, единственное, что приходит в голову - дизассемблировать код да сравнить, однако делать это лень):
Ну и на закуску - многие (и я в том числе) ленятся подключать терминал N, а используют автоиндексацию для задания количества итераций цикла for, а напрасно:
Двойной расход памяти, так как в сдвиговый регистр отправилась копия массива, плюс очевидные пенальти по производительности.
Дисклаймер - на вопросы "почему вот здесь буфер выделяется а вот тут - нет и там быстрее - а сям медленнее" отвечать довольно сложно, так как это лежит в большой степени на совести компилятора и небольшая модификация программы может привести к кардинальным изменениям. Где кроется истина - знает лишь NI, так что всё вышенаписанное не воспринимайте как аксиому - это просто пища для размышлений.
Ну и список литературы, ессно, там по большей части всё изложено:
In Place Element Structure
Array Index / Replace Elements Border Node
In Place Element Structures: Increasing Memory Efficiency
VI Memory Usage
Memory Management for Large Data Sets (раздел "Reducing Copies of Large Data Sets")
-
Igor_G
- assistant

- Сообщения: 126
- Зарегистрирован: 06 ноя 2011, 14:10
- Версия LabVIEW: 2012-2016
- Контактная информация:
Re: In Place Element Structure дает ли реальные преимуществ
Работает и дает положительный результат достаточно наглядно,
но испольсовать ее мне пока правильно достаточно сложно. Почему?
Это достаточно хорошо описал уже AndreyDmitriev.
но испольсовать ее мне пока правильно достаточно сложно. Почему?
Это достаточно хорошо описал уже AndreyDmitriev.
- Вложения
-
-
- Похожие темы
- Ответы
- Просмотры
- Последнее сообщение
-
- 6 Ответы
- 231 Просмотры
-
Последнее сообщение Artem.spb